 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPILLage: Agentic Oversharing on the Web
Feb 13, 2026LLM-powered agents are beginning to automate user's tasks across the open web, often with access to user resources such as emails and calendars. Unlike standard LLMs answering questions in a controlled ChatBot setting, web agents act "in the wild", interacting with third parties and leaving behind an action trace. Therefore, we ask the question: how do web agents handle user resources when accomplishing tasks on their behalf across live websites? In this paper, we formalize Natural Agentic Oversharing -- the unintentional disclosure of task-irrelevant user information through an agent trace of actions on the web. We introduce SPILLage, a framework that characterizes oversharing along two dimensions: channel (content vs. behavior) and directness (explicit vs. implicit). This taxonomy reveals a critical blind spot: while prior work focuses on text leakage, web agents also overshare behaviorally through clicks, scrolls, and navigation patterns that can be monitored. We benchmark 180 tasks on live e-commerce sites with ground-truth annotations separating task-relevant from task-irrelevant attributes. Across 1,080 runs spanning two agentic frameworks and three backbone LLMs, we demonstrate that oversharing is pervasive with behavioral oversharing dominates content oversharing by 5x. This effect persists -- and can even worsen -- under prompt-level mitigation. However, removing task-irrelevant information before execution improves task success by up to 17.9%, demonstrating that reducing oversharing improves task success. Our findings underscore that protecting privacy in web agents is a fundamental challenge, requiring a broader view of "output" that accounts for what agents do on the web, not just what they type. Our datasets and code are available at https://github.com/jrohsc/SPILLage.
ZK-APEX: Zero-Knowledge Approximate Personalized Unlearning with Executable Proofs
Dec 09, 2025Machine unlearning aims to remove the influence of specific data points from a trained model to satisfy privacy, copyright, and safety requirements. In real deployments, providers distribute a global model to many edge devices, where each client personalizes the model using private data. When a deletion request is issued, clients may ignore it or falsely claim compliance, and providers cannot check their parameters or data. This makes verification difficult, especially because personalized models must forget the targeted samples while preserving local utility, and verification must remain lightweight on edge devices. We introduce ZK APEX, a zero-shot personalized unlearning method that operates directly on the personalized model without retraining. ZK APEX combines sparse masking on the provider side with a small Group OBS compensation step on the client side, using a blockwise empirical Fisher matrix to create a curvature-aware update designed for low overhead. Paired with Halo2 zero-knowledge proofs, it enables the provider to verify that the correct unlearning transformation was applied without revealing any private data or personalized parameters. On Vision Transformer classification tasks, ZK APEX recovers nearly all personalization accuracy while effectively removing the targeted information. Applied to the OPT125M generative model trained on code data, it recovers around seventy percent of the original accuracy. Proof generation for the ViT case completes in about two hours, more than ten million times faster than retraining-based checks, with less than one gigabyte of memory use and proof sizes around four hundred megabytes. These results show the first practical framework for verifiable personalized unlearning on edge devices.
Membership and Memorization in LLM Knowledge Distillation
Aug 09, 2025



Recent advances in Knowledge Distillation (KD) aim to mitigate the high computational demands of Large Language Models (LLMs) by transferring knowledge from a large ''teacher'' to a smaller ''student'' model. However, students may inherit the teacher's privacy when the teacher is trained on private data. In this work, we systematically characterize and investigate membership and memorization privacy risks inherent in six LLM KD techniques. Using instruction-tuning settings that span seven NLP tasks, together with three teacher model families (GPT-2, LLAMA-2, and OPT), and various size student models, we demonstrate that all existing LLM KD approaches carry membership and memorization privacy risks from the teacher to its students. However, the extent of privacy risks varies across different KD techniques. We systematically analyse how key LLM KD components (KD objective functions, student training data and NLP tasks) impact such privacy risks. We also demonstrate a significant disagreement between memorization and membership privacy risks of LLM KD techniques. Finally, we characterize per-block privacy risk and demonstrate that the privacy risk varies across different blocks by a large margin.
Bifröst: Spatial Networking with Bigraphs
Jul 30, 2025Modern networked environments increasingly rely on spatial reasoning, but lack a coherent representation for coordinating physical space. Consequently, tasks such as enforcing spatial access policies remain fragile and manual. We first propose a unifying representation based on bigraphs, capturing spatial, social, and communication relationships within a single formalism, with user-facing tools to generate bigraphs from physical environments. Second, we present a hierarchical agent architecture for distributed spatial reasoning, with runtimes for agentic processes to interact the spatial representation, and a context-aware execution model that scopes reasoning to the smallest viable subspace. Together, these enable private, reliable, and low-latency spatial networking that can safely interact with agentic workflows.
Poster: Enhancing GNN Robustness for Network Intrusion Detection via Agent-based Analysis
Jun 25, 2025Graph Neural Networks (GNNs) show great promise for Network Intrusion Detection Systems (NIDS), particularly in IoT environments, but suffer performance degradation due to distribution drift and lack robustness against realistic adversarial attacks. Current robustness evaluations often rely on unrealistic synthetic perturbations and lack demonstrations on systematic analysis of different kinds of adversarial attack, which encompass both black-box and white-box scenarios. This work proposes a novel approach to enhance GNN robustness and generalization by employing Large Language Models (LLMs) in an agentic pipeline as simulated cybersecurity expert agents. These agents scrutinize graph structures derived from network flow data, identifying and potentially mitigating suspicious or adversarially perturbed elements before GNN processing. Our experiments, using a framework designed for realistic evaluation and testing with a variety of adversarial attacks including a dataset collected from physical testbed experiments, demonstrate that integrating LLM analysis can significantly improve the resilience of GNN-based NIDS against challenges, showcasing the potential of LLM agent as a complementary layer in intrusion detection architectures.
Energy-Aware Deep Learning on Resource-Constrained Hardware
May 18, 2025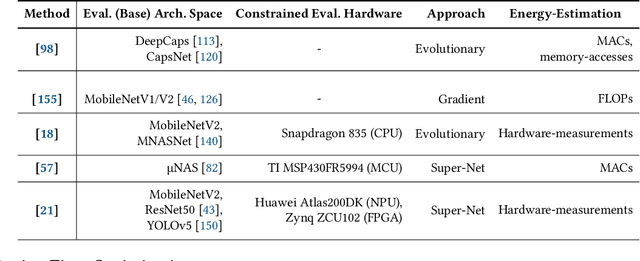
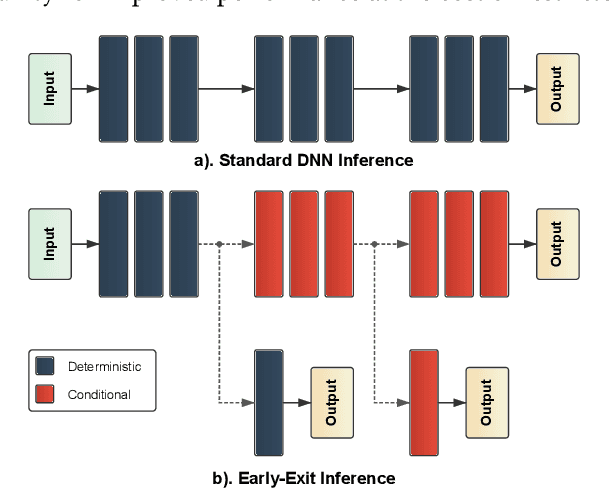
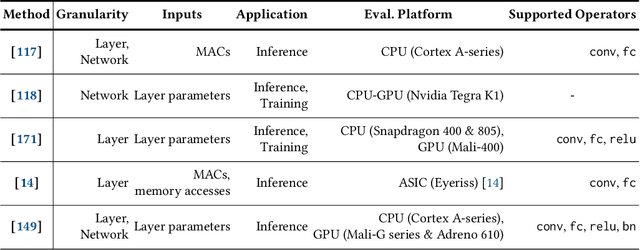
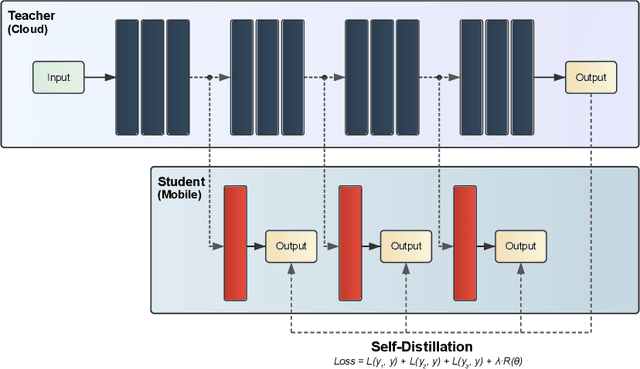
The use of deep learning (DL) on Internet of Things (IoT) and mobile devices offers numerous advantages over cloud-based processing. However, such devices face substantial energy constraints to prolong battery-life, or may even operate intermittently via energy-harvesting. Consequently, \textit{energy-aware} approaches for optimizing DL inference and training on such resource-constrained devices have garnered recent interest. We present an overview of such approaches, outlining their methodologies, implications for energy consumption and system-level efficiency, and their limitations in terms of supported network types, hardware platforms, and application scenarios. We hope our review offers a clear synthesis of the evolving energy-aware DL landscape and serves as a foundation for future research in energy-constrained computing.
TeleSparse: Practical Privacy-Preserving Verification of Deep Neural Networks
Apr 27, 2025

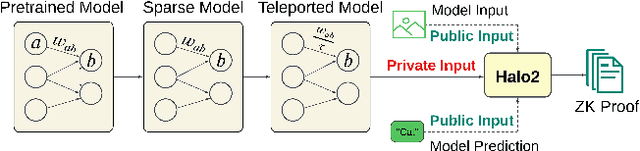
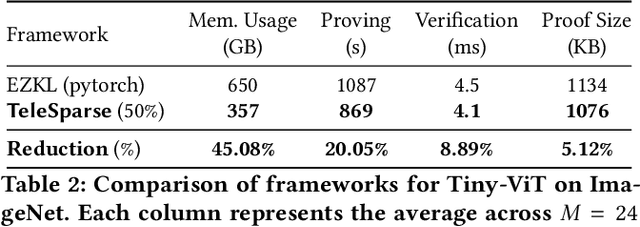
Verification of the integrity of deep learning inference is crucial for understanding whether a model is being applied correctly. However, such verification typically requires access to model weights and (potentially sensitive or private) training data. So-called Zero-knowledge Succinct Non-Interactive Arguments of Knowledge (ZK-SNARKs) would appear to provide the capability to verify model inference without access to such sensitive data. However, applying ZK-SNARKs to modern neural networks, such as transformers and large vision models, introduces significant computational overhead. We present TeleSparse, a ZK-friendly post-processing mechanisms to produce practical solutions to this problem. TeleSparse tackles two fundamental challenges inherent in applying ZK-SNARKs to modern neural networks: (1) Reducing circuit constraints: Over-parameterized models result in numerous constraints for ZK-SNARK verification, driving up memory and proof generation costs. We address this by applying sparsification to neural network models, enhancing proof efficiency without compromising accuracy or security. (2) Minimizing the size of lookup tables required for non-linear functions, by optimizing activation ranges through neural teleportation, a novel adaptation for narrowing activation functions' range. TeleSparse reduces prover memory usage by 67% and proof generation time by 46% on the same model, with an accuracy trade-off of approximately 1%. We implement our framework using the Halo2 proving system and demonstrate its effectiveness across multiple architectures (Vision-transformer, ResNet, MobileNet) and datasets (ImageNet,CIFAR-10,CIFAR-100). This work opens new directions for ZK-friendly model design, moving toward scalable, resource-efficient verifiable deep learning.
NoEsis: Differentially Private Knowledge Transfer in Modular LLM Adaptation
Apr 25, 2025Large Language Models (LLM) are typically trained on vast amounts of data from various sources. Even when designed modularly (e.g., Mixture-of-Experts), LLMs can leak privacy on their sources. Conversely, training such models in isolation arguably prohibits generalization. To this end, we propose a framework, NoEsis, which builds upon the desired properties of modularity, privacy, and knowledge transfer. NoEsis integrates differential privacy with a hybrid two-staged parameter-efficient fine-tuning that combines domain-specific low-rank adapters, acting as experts, with common prompt tokens, acting as a knowledge-sharing backbone. Results from our evaluation on CodeXGLUE showcase that NoEsis can achieve provable privacy guarantees with tangible knowledge transfer across domains, and empirically show protection against Membership Inference Attacks. Finally, on code completion tasks, NoEsis bridges at least 77% of the accuracy gap between the non-shared and the non-private baseline.
* ICLR 2025 MCDC workshop
Intelligent Detection of Non-Essential IoT Traffic on the Home Gateway
Apr 22, 2025



The rapid expansion of Internet of Things (IoT) devices, particularly in smart home environments, has introduced considerable security and privacy concerns due to their persistent connectivity and interaction with cloud services. Despite advancements in IoT security, effective privacy measures remain uncovered, with existing solutions often relying on cloud-based threat detection that exposes sensitive data or outdated allow-lists that inadequately restrict non-essential network traffic. This work presents ML-IoTrim, a system for detecting and mitigating non-essential IoT traffic (i.e., not influencing the device operations) by analyzing network behavior at the edge, leveraging Machine Learning to classify network destinations. Our approach includes building a labeled dataset based on IoT device behavior and employing a feature-extraction pipeline to enable a binary classification of essential vs. non-essential network destinations. We test our framework in a consumer smart home setup with IoT devices from five categories, demonstrating that the model can accurately identify and block non-essential traffic, including previously unseen destinations, without relying on traditional allow-lists. We implement our solution on a home access point, showing the framework has strong potential for scalable deployment, supporting near-real-time traffic classification in large-scale IoT environments with hundreds of devices. This research advances privacy-aware traffic control in smart homes, paving the way for future developments in IoT device privacy.
Robust Hallucination Detection in LLMs via Adaptive Token Selection
Apr 10, 2025Hallucinations in large language models (LLMs) pose significant safety concerns that impede their broader deployment. Recent research in hallucination detection has demonstrated that LLMs' internal representations contain truthfulness hints, which can be harnessed for detector training. However, the performance of these detectors is heavily dependent on the internal representations of predetermined tokens, fluctuating considerably when working on free-form generations with varying lengths and sparse distributions of hallucinated entities. To address this, we propose HaMI, a novel approach that enables robust detection of hallucinations through adaptive selection and learning of critical tokens that are most indicative of hallucinations. We achieve this robustness by an innovative formulation of the Hallucination detection task as Multiple Instance (HaMI) learning over token-level representations within a sequence, thereby facilitating a joint optimisation of token selection and hallucination detection on generation sequences of diverse forms. Comprehensive experimental results on four hallucination benchmarks show that HaMI significantly outperforms existing state-of-the-art approaches.